Van's homepage
A child exploring the world alone.
A neural network approach for climate classification - Sec 3. Climate features and simple SOM clustering
by Van
Sec 2. discussed the results of NN vegetation mapping. In this section we will derive and analyze the climate features, and then do a preliminary clustering on the features.
The three principal features are the keys to understand the climate classification schemes derived afterwards.
Climate features
Climate features were extracted by propagating the climate normal dataset through the trained network and then retrieving the activations of the concat layer. The concat layer derives 512 climate features for clustering. It is not feasible to analyze them one by one, so principal component analysis (PCA) was applied first. Out of the 512 components after PCA, 15 components explained over 90% of the information. The most prominent three components on the 1991-2020 climate normals dataset are plotted and explained below.
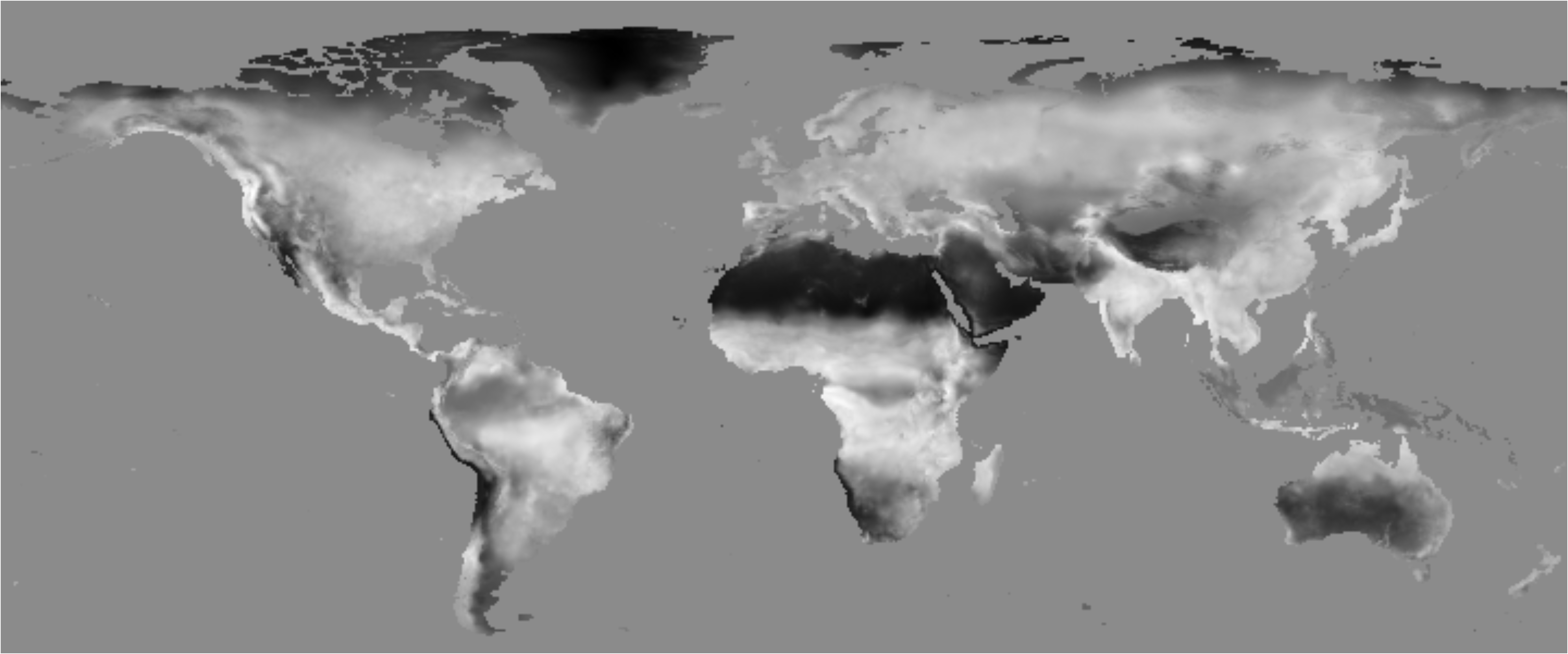 Three principal climate features extracted by the network. Brighter regions represent higher values. From top to bottom, feature 1, explaining 36.34% of information, implies damp-coldness. Feature 2, explaining 16.67%, can be regarded as continentality. Feature 3, explaining 14.29%, indicates the seasonal contrast in growth capability. The explained variance of the fourth feature significantly drops to 6.56%, so we are not going to analyze it further.
Three principal climate features extracted by the network. Brighter regions represent higher values. From top to bottom, feature 1, explaining 36.34% of information, implies damp-coldness. Feature 2, explaining 16.67%, can be regarded as continentality. Feature 3, explaining 14.29%, indicates the seasonal contrast in growth capability. The explained variance of the fourth feature significantly drops to 6.56%, so we are not going to analyze it further.
Continentality basically represents aridity. For two observations with similar aridity, the one with colder temperature has a higher value.
Köppen’s measurement for continentality is indirect and unclear. He used summer temperature as a criterion for the a, b, c subtype, where a moderate summer (b or c subtype) indicates oceanic characteristics. He even used a d subtype according to winter temperature to mark the extreme continentality in Eastern Siberia. Also, the main group D was originally named the
continentalgroup by Köppen, though nowadays many climatologists don’t prefer this term and instead call it thecoldgroup. Our data science method tells us the intricacies of continentality.
The first feature which I call it damp-coldness basically represents (winter) temperature level. For two observations with similar temperature, the one with less aridity has a higher value. Hopefully someone could give this feature a better name. This feature largely agrees with Köppen’s criterion among the A, C, D major groups.
Warmth is naturally linked with dryness by causing higher evaporation. In view of this fact, temperature level and aridity are not independent, while principal components are required to be independent. PCA on the learned climate features defines this new climate term (the first feature) for us - the orthogonal counterpart of continentality. These two features form the orthogonal basis on the temperature-precipitation/aridity plane.
The third feature, seasonality, represents the starkness of growing season. For example, the savanna climate has a high value of this feature due to its distinct dry-wet season pattern. The rainforest climate has a low value because the condition is almost constantly good all year round. Comparing with an icecap or hot desert climate which also has no seasonal variations, the rainforest climate has a higher value because its growing condition is obviously better.
Although related to precipitation pattern, this seasonality feature derived by us is different from Köppen’s classification criterion for the f, w, s subtypes. The growing condition is comprehensively considered rather than the empirical precipitation concentration in the so-called summer/winter. That is one of the reasons why in our climate classification scheme the Mediterranean characteristic is not pronounced, as you can see later.
With the decreasing proportion of information explained, the climatological or biophysiological meanings of the features become more obscure and harder to interpret. Still from the three illustrated, we can see that the network did learn a lot of informative features that indicate the underlying land cover conditions. The map below locates the places with the extremities of the features, based on 1991-2020 climate normals, Antarctica excluded. Right-click for full image.
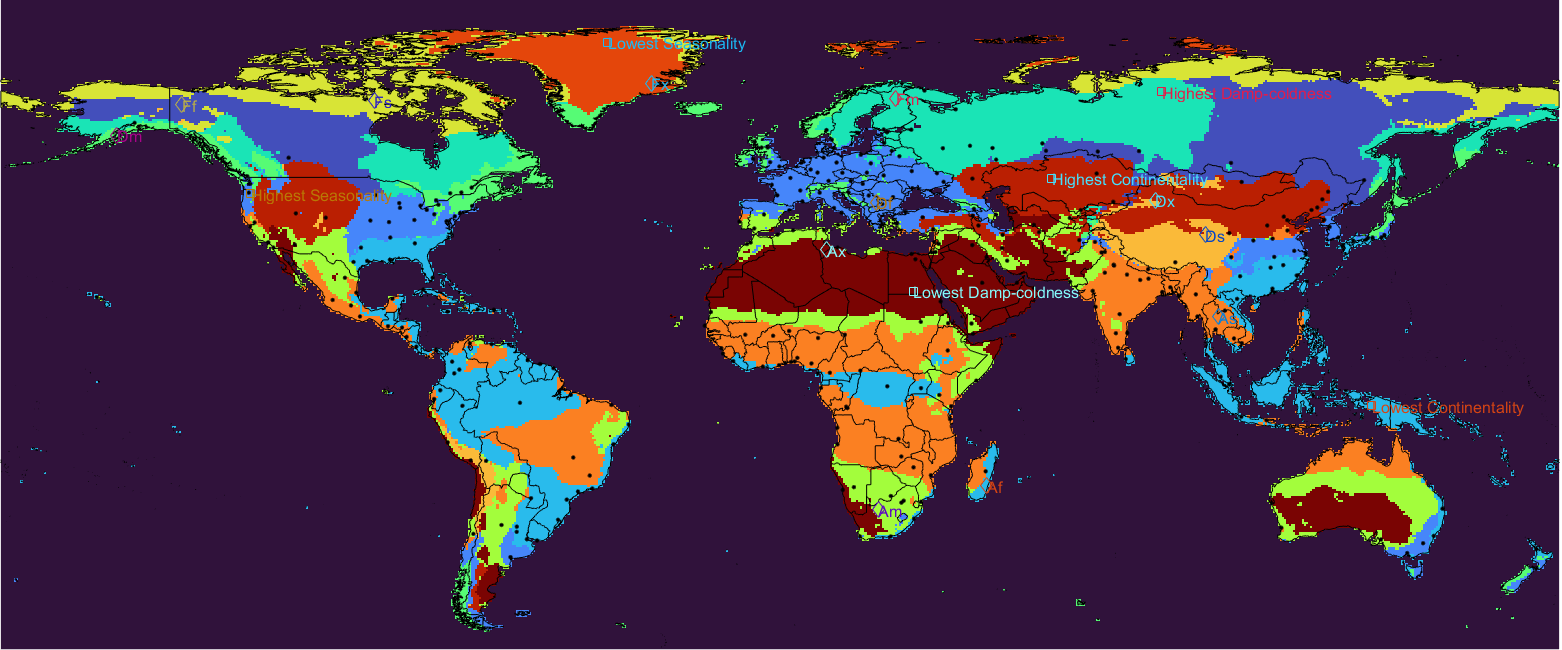
The place with the highest damp-coldness is in the Putorana Mountains just south of Norilsk, Krasnoyarsk Krai, Russia. Lowest is in the Sahara Desert, northwest of Abu Simbel, Egypt.
The place with the highest continentality is in Central Kazakhstan, southwest of the town Shubalan. Lowest is near Puncak Jaya, Indonesia.
The place with the highest seasonality is near Mount Hook, just west of Portland, Oregon, US. Lowest is in the central north of Greenland.
Why SOM?
Recall that in the Köppen scheme, especially within the main groups C and D, the structure is highly organized (as 2D tables in my article). Naturally and as illustrated above, temperature, aridity and seasonality are three main axes for the climate space. In view of this fact and for the sake of human interpretability of the proposed climate classification scheme, it’s best to adopt a clustering method that preserves and highlights the intrinsic topology of the climate space, and that’s where self-organizing map (SOM) comes to help. Basically it’s a centroid-based clustering method just like $k$-means, but it enforces a pre-set topology of clusters by an ordering phase in training.
If a large number of neurons are pre-set, it actually does not enforce any topology. Data fall into the closest neuron to present their topology by the activation strength of different neurons after training finishes. In this way, like BIRCH, SOM functions as a preliminary dimension-reduction method and leaves the intermediate result for other clustering methods. We don’t take this route at this time. We will investigate the topology of our climate features beforehand and enforce a topology that combines human knowledge of climates and data analysis, using SOM as a clustering method directly.
To address the shortcoming of the simple scheme derived by this simple method, later we will leverage the above methodology and derive a climate classification scheme with more details.
Choice of SOM topology
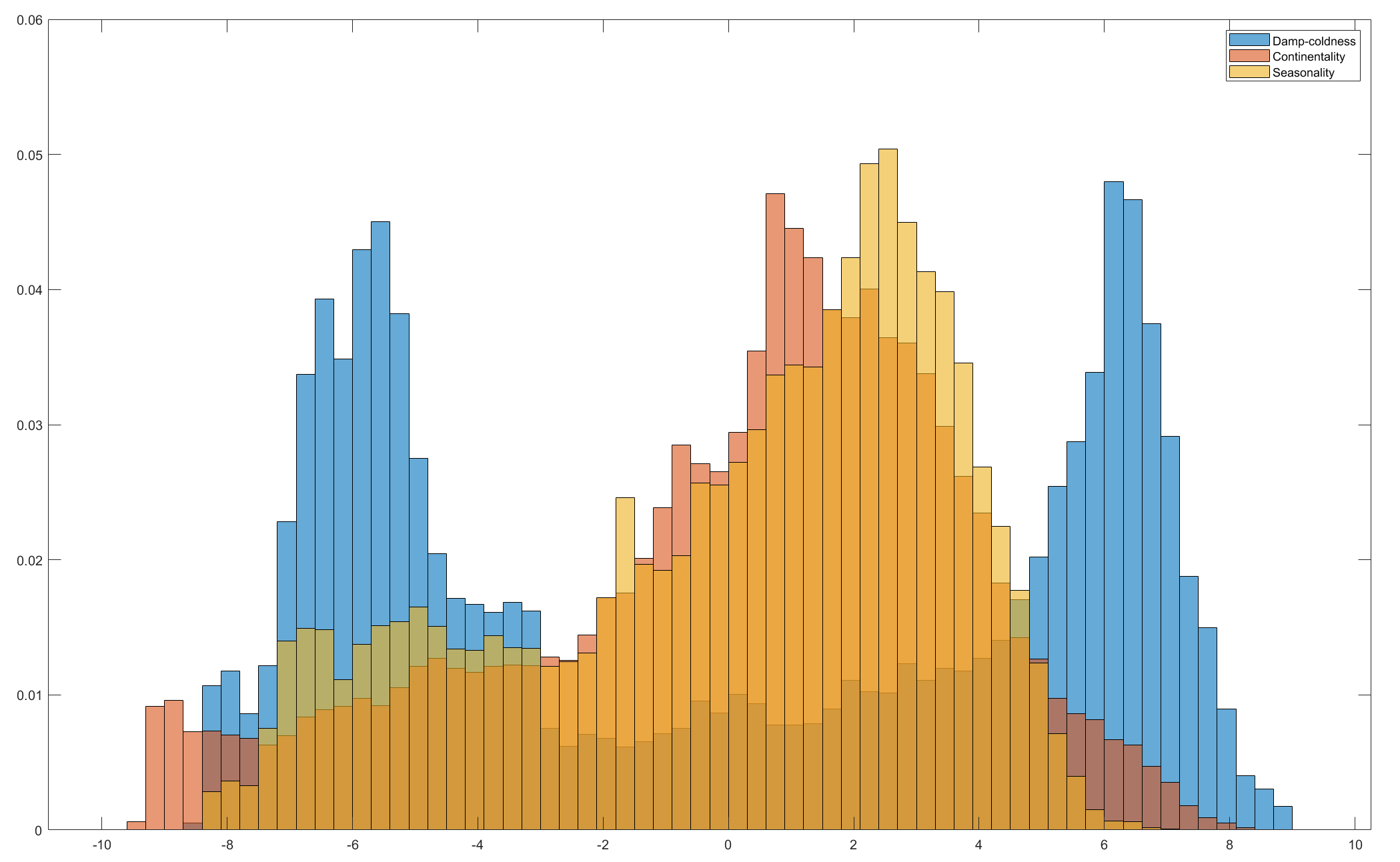
Histogram of the three principal features. Right-click for full image.
From the histogram it can be seen that the distribution of damp-coldness (in blue) has two peaks with a transitional interval. The two peaks can be regarded as the vast warm (tropical plus subtropical) zone and the cold (arctic plus subarctic) zone. The temperate zone, sitting in the interval, actually does not cover a large portion of land. On the other hand, the distributions of the other two features are both right-leaning, indicating that the continental area is larger than the non-continental area, and that the area with seasonal climatic characteristics is larger than the non-seasonal. By this analysis we can see the climate types should roughly follow a $3 \times 2 \times 2$ scheme.
The standard deviation of the three features are 5.41, 3.66, 3.39 respectively, roughly following the 3:2:2 ratio. The standard deviation of the fourth feature significantly drops to 2.30, so a 3D SOM is good to work. Usually the SOM uses a hexagonal topology; we will make no exception here.
Result
Following what we did in NN training, we use all the $21 \times 66501 = 1396521$ instances in clustering, covering 21 annual sets of climate normals. Each instance has 15 features (i.e., a $1 \times 15$ vector). The SOM derives 12 cluster centroids through training, with which we could assign clusters (climate types) for each set of climate normals. In this way the climate classification model remains constant through the years, and historical analysis could make sense.
Surely due to the accelerating climate change, when necessary (for example once every decade), the model could be re-trained with the newest climate and land cover data. This is one of the strengths of our data-oriented method - it’s easy to update the model.
The trained NN, PCA and SOM models are three components of our climate classification scheme. When we would like to classify the climate for a place, feed the climate data into the trained NN, let the output of the
concatlayer go through the trained PCA (which is a linear transform), pick the first 15 principal components and find its nearest neighbor among the 12 SOM cluster centroids.
 The $3 \times 2 \times 2$ SOM scheme on climate features, based on 1991-2020 climate normals. The climate features are the output of the
The $3 \times 2 \times 2$ SOM scheme on climate features, based on 1991-2020 climate normals. The climate features are the output of the concat layer of the NN. Color scheme see Sec 4. Right-click for full image.
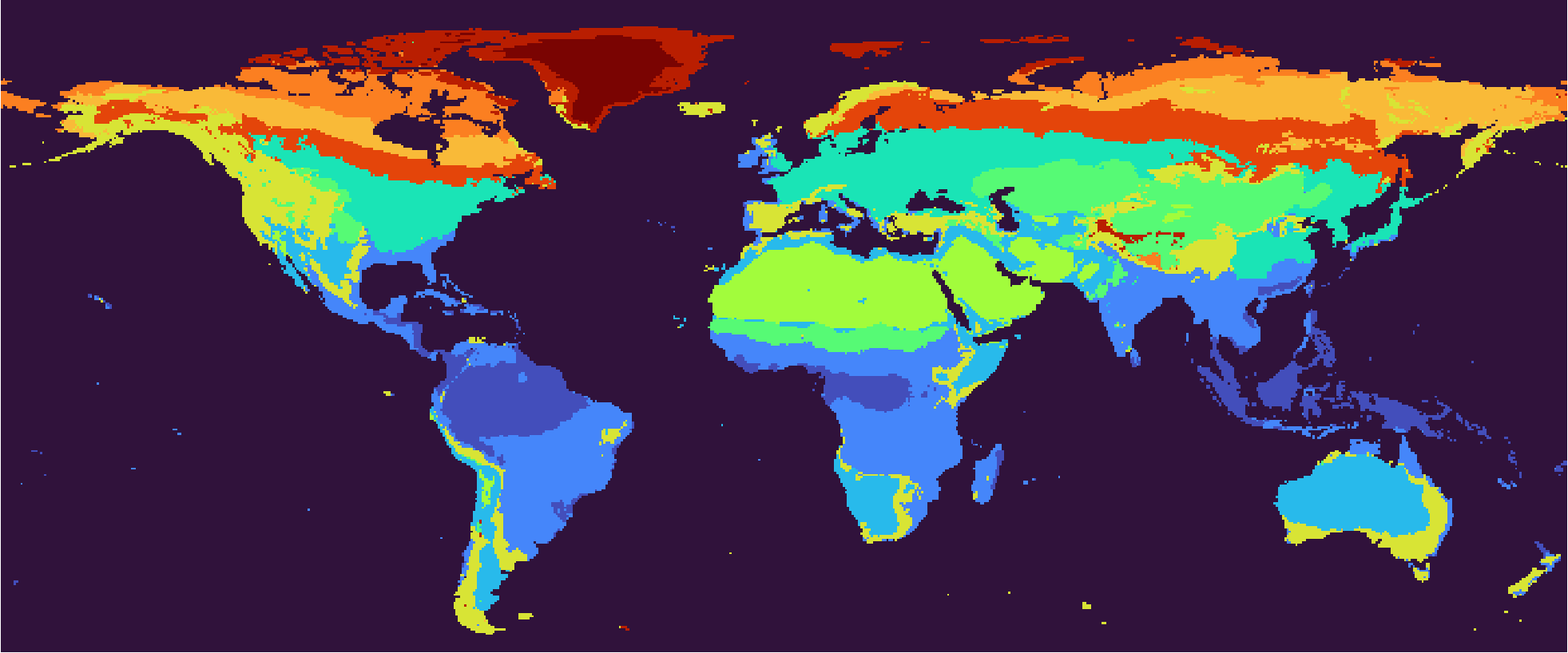 The output of the same methodology applied on biome features, based on 1991-2020 climate normals. The biome features are the output of the
The output of the same methodology applied on biome features, based on 1991-2020 climate normals. The biome features are the output of the relu-2 layer of the NN. Compared with climate features, one regression block is passed through. The clusters are not named. Right-click for full image.
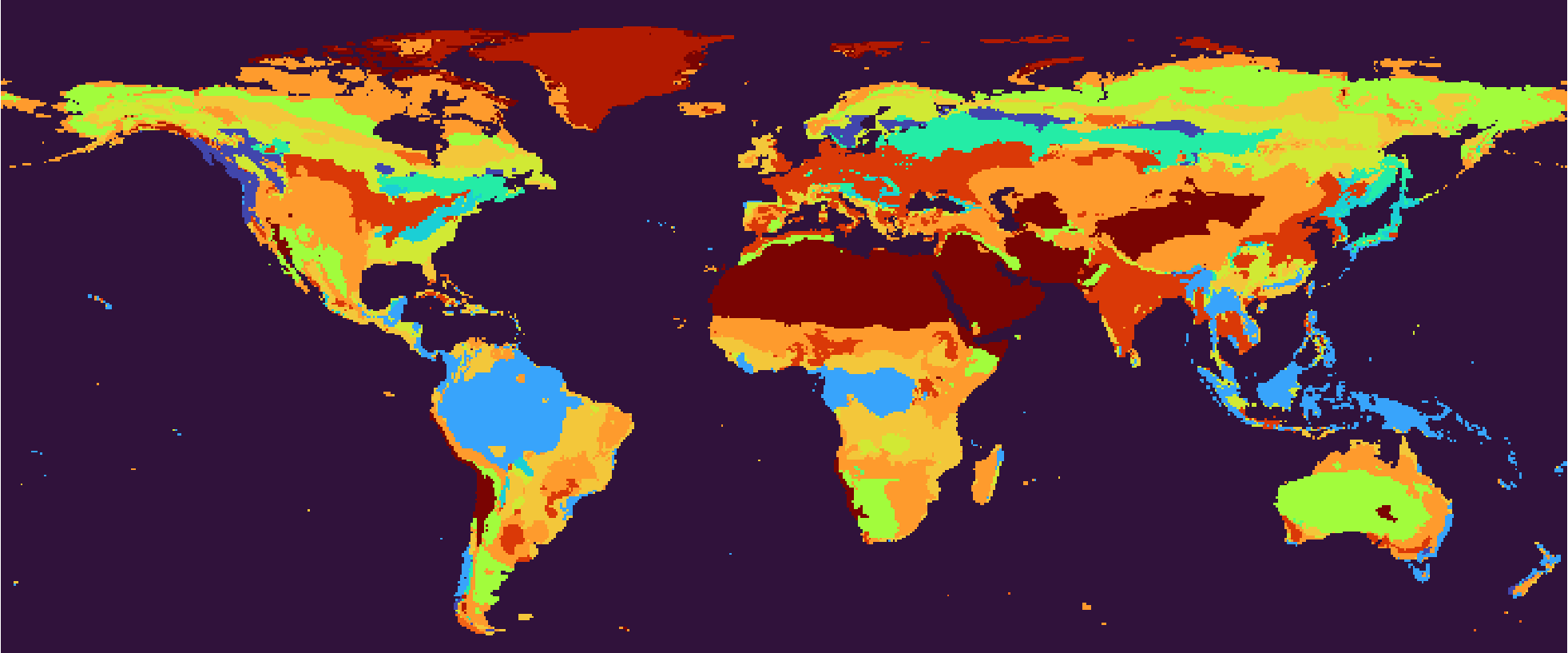 The output of the NN (predicted land cover). Compared with biome features, one more regression block is passed through. Color scheme see Sec 2. Right-click for full image.
The output of the NN (predicted land cover). Compared with biome features, one more regression block is passed through. Color scheme see Sec 2. Right-click for full image.
Detailed interpretation and analysis of this scheme will come in the next section. Here I would like to discuss about the difference between climate classification and biome classification again. It can be seen that the biome classification is closer to the land cover, hiding the climatic conditions. For example, as mentioned in Preface, Northeast China is assigned the same cluster with the Yangtze River Plain, as well as the Europe, Western Siberia and Northeastern US. Also, the Australian desert receives a different biome classification with the Sahara desert, while in climate classification their behavior are similar. One prominant difference lies in Northern Canada and the vast Siberia, where in biome classification the boundaries are latitudinal and in climate classification they are longitudinal. How do the similar climate conditions result in different biomes? It can be an interesting topic for further discussion. From a standpoint of the data model, the question asks for investigation into how the NN’s regression block works. The fc-2 layer assigns different weights to different climate features, exaggerating the slight climatic differences in certain areas. This reflects different vegetation types’ preferences or sensitivities for climate features. The ecology community should already have an answer to this, and we are just seeking a fit to data models.
It can be seen in the Köppen scheme the dividing lines in the boreal are latitudinal. Without the data model it’s really hard to distinguish between climate classification and biome classification.
How do the different climate conditions result in “similar biomes”? This one is easy to answer. The so-called “similar biomes” are not truly similar, but a limitation of our land cover scheme. The land cover types are not granular enough to reflect the differences between some areas. For example, even though Northeast China and the Yangtze River Plain are both predominated by crops and forests, the species are different. This difference in species is not sufficiently reflected in the land cover types. If we have a different land cover scheme, it will definitely lead to a different climate classification under our methodology. For instance, if the land cover scheme has a distinct Mediterranean vegetation type, the Mediterranean climate type would definitely be more pronounced in the result.
tags:I’m not going to look into biome classification in this series. Maybe later, or for someone who is interested.